We have made tests of the behaviour of the Exemplar when running multiple
Objectivity database clients. Firstly we demonstrated that a 64-CPU hypernode
could be fully loaded by spreading 64 database clients evenly across the
hypernode. Then we examined the performance of database client applications as a
function of the number of concurrent clients of the database, and compared the
results with the performance on the single-CPU HP 755 workstation.
The results showed that the elapsed time per query for database applications
executed on the Exemplar was independent of the number of of other clients, at
least in the region up to 64 clients (the tests were executed on a 64-CPU
hypernode). The elapsed time per query on the single-CPU system, however, was
predictably affected by the number of simultaneous queries. Evidently, 64
individual workstations could also execute 64 queries in the same time, but the
advantage of the Exemplar is that only one copy of the database is required, and
we expect to see some benefit from clients who find the database already in the
Exemplar filesystem cache.
We noted some instability of the ODBMS when running with large numbers of
simultaneous queries, in particular the software process that controls database
locking, the "lockserver", became bogged down in some cases. In subsequent
tests, we ran the lockserver on a separate machine (a convenient feature of
the Objectivity/DB system).
The multiple client tests were continued
by putting a workload of N reconstruction processes on the Exemplar, for
N in the range 15 - 210. The processes were reading independent data sets located in
database files on
two node /tmp filesystems. The two node filesystems had a maximum combined
throughput (for reading only) of about 44 MBytes/sec. The reconstruction processes were
divided evenly over all 15 batch complex nodes.
The object were read via a simple read-ahead optimisation layer
which ensured that database I/O was made in sequential bursts of 2 MBytes.
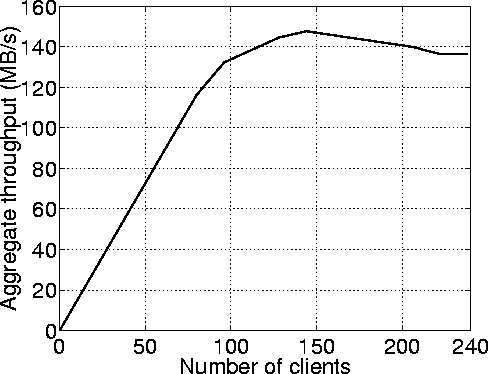
The system throughput was measured (expressed in MBytes/sec aggregate data rate) versus
the number of running reconstruction processes N. As N increased, the system
went from being CPU-bound (insufficient CPUs used to saturate the available disk
bandwidth) to being disk-bound (insufficient disk bandwidth to fully
load the CPUs used).
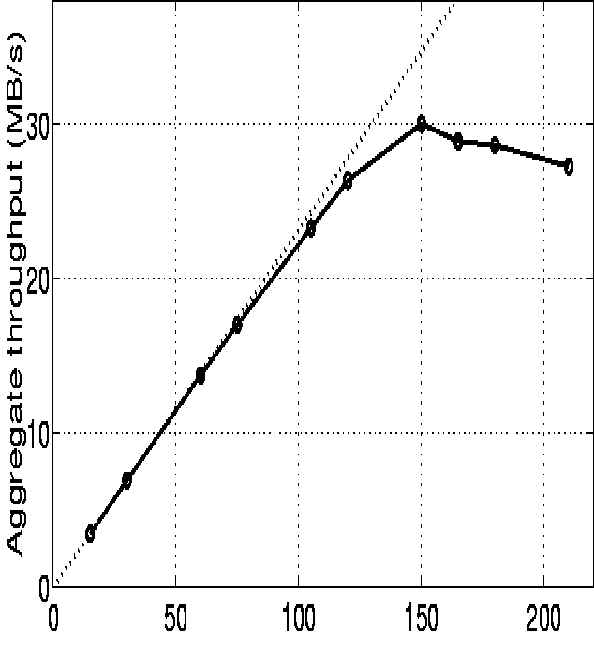
The results obtained are shown below, where the dotted line
depicts the theoretical maximum throughput (equal to the I/O demand of all
processes if they would have no I/O latency). There is an almost perfect speedup
curve until the disk subsystems become saturated at N=150 processes and 30 MB/s.
The results show the Exemplar running Objectivity/DB to be well suited for
handling the reconstruction workload. With two node filesystems it was
possible to use up to 120 processors in parallel with an extremely efficient utilisation
of allocated CPU power and I/O
resources.