Koen Holtman, 20 Apr 1998
INTRODUCTION
Track reconstruction in high energy physics is highly CPU-intensive with modest I/O requirements. Track reconstruction needs to be done for large sets of events. For each event, track reconstruction can proceed independently. This makes the process highly parallelisable, and allows I/O to be done in a `streamed' way. According to the CMS CTP the parameters for CMS track reconstruction are
EXPERIMENT
We put a workload of N (simulated) reconstruction processes on the Exemplar, for N in the range 15 - 210.
The parameters of the reconstruction processes were as follows.
for(;;)
{
read next 10 KB object;
compute for 0.045 CPU seconds;
}
The 10 KB objects are clustered in the order of reading. Each process has its own database (130 MB) of objects, and reads through them cyclicly.
The processes were reading independent data sets located in database files on two node /tmp filesystems. The two node filesystems have a maximum combined throughput (for reading only) of about 44 MB/s. Reconstruction processes were divided evenly over all 15 batch complex nodes.
RESULTS
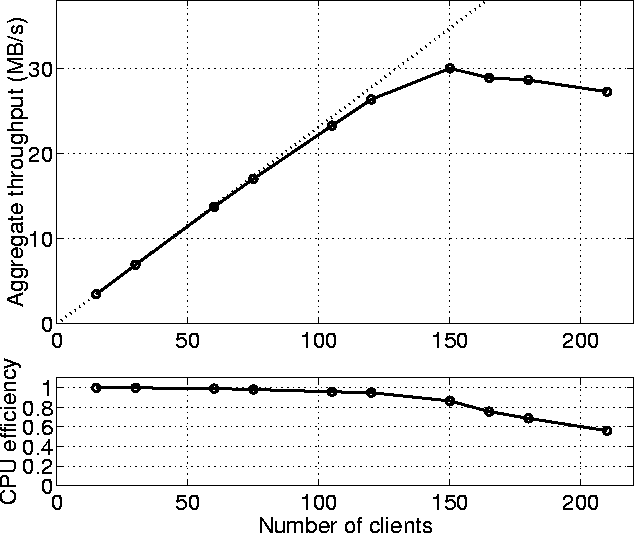
We measured the system throughput (expressed in MB/s aggregate data rate) versus the number of running reconstruction processes N. As N increased, the system went from a CPU-bound one (not enough CPUs used to saturate available disk bandwidth) to a disk-bound one (not enough available disk bandwidth to fully load CPUs used).
A plot of the results is in the upper part of the figure below. The dotted line is the theoretical maximum throughput (which is equal to the I/O demand of all processes if they would have 0-latency I/O). We have an almost perfect speedup curve until the disk subsystems become saturated at N=150 processes and 30 MB/s.
The lower part of the figure shows the `CPU efficiency' which is the fraction of time in which the CPUs allocated to the processes work on executing the (simulated) track reconstruction code.
EFFECT OF THE READ-AHEAD LAYER
We noted above that the reconstruction code accesses the database through a read-ahead layer. This layer (which consists of about hundred lines of C++ code) was developed by us in the past to achieve good I/O performance in some scenarios on smaller systems.
In a test with the layer disabled, performance degraded with a factor 2. Below 60 processes, the throughput was close to the theoretical maximum, above 60 processes it levelled out at 15 MB/s.
PRELIMINARY CONCLUSIONS
The Exemplar seems to be very well suited for handling a HEP reconstruction workload. With 2 node filesystems it was possible to use up to 120 processors in parallel with an extremely efficient utilisation of allocated CPU power and I/O resources.
It is likely that efficient use of more CPUs is possible when more than 2 node filesystems are used in parallel -- this is a subject for future tests.
It is important to note that this high efficiency was achieved using a standard commercial object database with a semi-standard read-ahead layer on top as the I/O engine. We did not have to invest in hardware-dependent or application-dependent I/O optimisations in the (simulated) track reconstruction code.
The test with disabling the read-ahead layer showed the importance of this optimisation. A case can be made for incorporating the functionality of the read-ahead layer into future commercial object database products.
These conclusions are preliminary because no writing of result data was done -- this is a subject of future tests. It is possible that scalability will be less good if writing is introduced. Writing will produce a higher load on the transaction and locking mechanisms of the object database and the scalability of these mechanisms is an area of concern.