GIOD - Globally Distributed Object Databases
for Physics Event Analysis at the Large Hadron Collider
A Caltech/CERN/HP Joint Project
The Large Hadron Collider will begin operation in 2005 at CERN in Geneva, Switzerland. The two largest experiments which will take data at the collider (CMS and ATLAS) have already submitted detailed plans for detectors and computing software systems. These will enable physicists to successfully capture and analyse the billions of highly complex interactions expected to occur in the detectors. The raw data rate of around 100 MBytes/second amounts to an expected accumulation of several PetaBytes of event data per year starting at the collider turn-on, and continuing for many years thereafter. The recorded data will be analysed by thousands of physicists at their home institutes around the World.
Both CMS and ATLAS plan to store and distribute the event data using distributed Object Database Management Systems (ODBMS) coupled with hierarchical storage management systems. Both are necessary to accomodate the complexity and sheer volume of the data, the geographical dispersion of the collaborating institutes and the large number of participating physicists.
The GIOD project is addressing this unprecedented challenge for data storage, access and networking computing technology, and its bearing on the entire Object Oriented software development task. The advantages and limitations of Object Database and Storage Management systems as applied to PetaBytes of data are being examined in the context of the probable distribution of computing resources in the collaborations. Particular attention is being paid to how the software should correctly implement and utilise the known, and often complex, relationships between the physics objects stored in the ODBMS. Use is being made of pre-funded hardware, financial support from Hewlett Packard, and participation by experts from CERN's IT and ECP Divisions.
This document describes the achievements so far, and the continuing goals of GIOD. The original project proposal can be found at http://pcbunn.cacr.caltech.edu/.
We are making use of several existing leading edge hardware and software systems, namely the Caltech HP Exemplar, a 256-PA8000 CPU next-generation SMP computer (~ 0.1 TIPS), the High Performance Software System from IBM, which is hierarchical storage management hardware and software, the Objectivity/DB Object Database Management System, and various high speed Local Area and Wide Area network infrastructures.
The Exemplar is a NUMA machine with 64 GBytes of main memory, shared amongst all 256 processors. It runs the SPP-UX Unix operating system, which is binary compatible with HP-UX. The processors are interconnected using a CTI toroidal wiring system, which gives excellent low-latency internode communication. Two HiPPI switches also connect the nodes. There is over 1 TeraByte of disk attached to the system, which can achieve up to 1 GigaByte/sec parallel reads and writes. Fast Ethernet and ATM connections are available. The machine is located at, and operated by, the Caltech Centre for Advanced Computing Research (CACR). Funding for the machine is by a joint Caltech/JPL/NASA project, not related to GIOD. The Exemplar will be replaced in 1999 by a "Merced" based system of 64 CPUs. In the interim, the PA8000 CPUs may be replaced by PA8200s.
We are also using several Pentium-class PCs running Windows/NT, and a couple of HP model 755 workstations. An HP model C200 workstation equipped with ATM has been ordered.
The HPSS installed at CACR runs on twin IBM machines attached to a 10(?) TByte tape robot with SSA disk buffers. The IBM machines are connected over HiPPI to the Exemplar.
The Objectivity/DB ODBMS is licensed for the Exemplar and workstations being used in the project. It is a pure object database that includes C++ and Java bindings, federations of individual databases, and the possibility of wide area database replication. We have also installed the Versant ODBMS, and are comparing its functionality and inter-ODBMS migration issues.
The Exemplar, HPSS and workstation systems are interconnected on the LAN using standard Ethernet and/or with HiPPI, and eventually we will also use 155 Mbit/sec ATM. Wide area connections between these systems and CERN (over a 4 Mbit/sec trans-Atlantic link) are being used in tests of distributed database "federations". A "SCENIC" OC12 link between CACR and the San Diego Supercomputer Centre (SDSC) will be used for WAN database tests in 1998 between the Exemplar and a large peer system in San Diego.In addition, CACR will avail itself of Internet 2/NGI national connections and peering with ESNET in 1998/1999.
Participants in the project include: Eva Arderiu-Ribera/CERN, Julian Bunn/CERN, Vincenzo Innocente/CERN, Anne Kirkby/Caltech, Paul Messina/Caltech, Harvey Newman/Caltech, James Patton/Caltech, Rick Wilkinson/Caltech and Roy Williams/Caltech.The project is led jointly by Julian Bunn and Harvey Newman.The HP funding and interests are managed by Greg Astfalk/HP.
We have installed version 4.0.8 of the Objectivity/DB ODBMS on the Caltech Exemplar, an HP 755 workstation, a Pentium II PC and a Pentium Pro PC. Using these installations we have used a simple OO test application to measure the performance and usability of the Object database as a function of its size, querying methods, platform, database location, cache size, and number of simultaneous database "users".
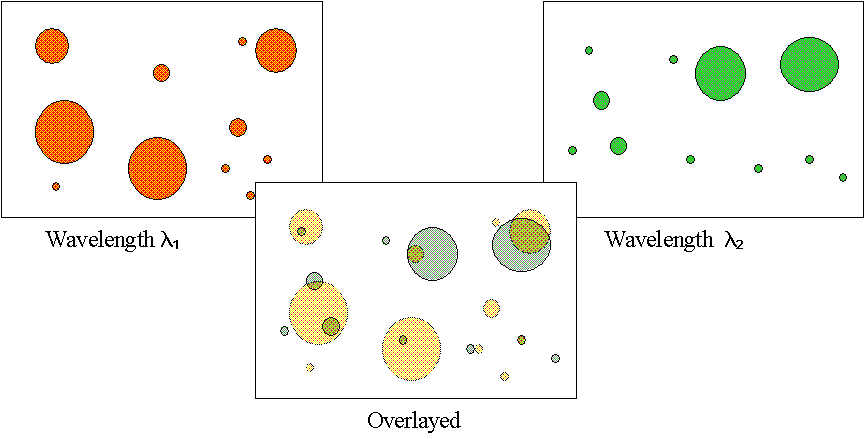
The test application is code that addresses the following problem domain: A region of the sky is digitized at two different wavelengths, yielding two sets of candidate bright objects, each characterised by a position (x,y) and width (sigma). The problem is to find bright objects at the same positions in both sets, consistent with the width of each. The figure below illustrates the problem.
We define a schema that specifies"star" objects with the following data members:
float xcentre; // X position of object
float ycentre; // Y position of object
float sigma; // width of object
int catalogue; // catalogue number of object
with associated member functions that return the position, the sigma, the catalogue number, the proximity of a point (X,Y) to the "star", and so on.
The application is in two parts: the first part generates a randomly-distributed set of stars in each of two databases. The second part attempts to match the positions of each star in the first database with each star in the second database, in order to find the star in the second database that is most close to the star in the first.
We expect the matching time to scale as N**2, where N is the number of stars in each database.
This application, while not taken from High Energy Physics, is analogous to matching energy deposits in a calorimeter with track impact positions, which is a typical event reconstruction task.
The application has the advantage that it is small, and easy to port from one OS to another, and from one ODBMS to another.
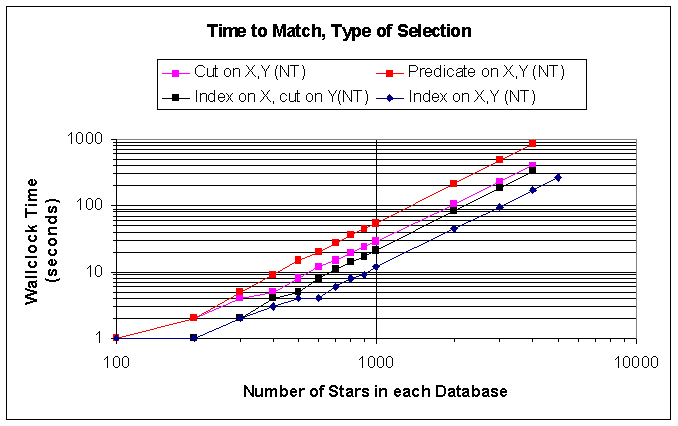
Matching speed as a function of the number of objects in each database
We define a "window" around the target object in the first database, and select as candidates only those objects in the second database that are situated inside the window. For each of the candidate objects we evaluate a "proximity" function with the target object, and select the candidate with the largest value for this function.Given the "window" coordinates in the second database, we can select stars there using (at least) four methods:
Using the class iterators provided by the database, with a cut in standard C++
Using the class iterator with a predicate (i.e. a text string that is evaluated for each target object and used to generate an iterator over the candidate objects in the second database)
Using an index on the stars in X, and an index in Y, and selecting only those candidates in the required range of X and Y. We expect that an index will result in a speedup of the matching process to order N.log(N) (?)
Using just the index on X (say), and then a cut on Y. This method is a hybrid of the first and previous methods described above.
The results using these different methods are shown below (the applications were executed on a Pentium PC):
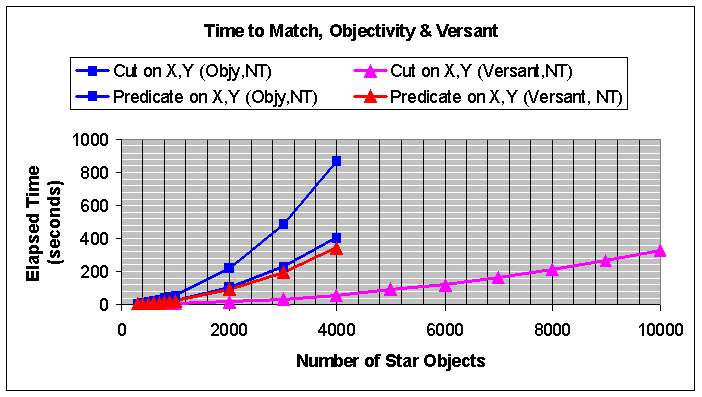
The results show that, as expected, the fastest times are obtained by using the index approach, and the slowest times are obtained using the text-based predicate.
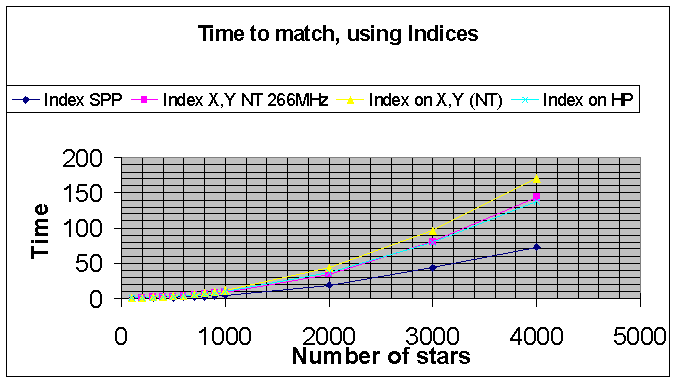
Matching speeds on different hardware/OS
In these tests, we compared the performance of the matching using indices, when executed on the Exemplar, the Pentium II (266 MHz), Pentium Pro (200 MHz) and HP 755 workstation. For all these tests, it can be shown that both stars databases were completely in system cache, and we can disregard effects due to disk access speeds on the various machines. The results are shown below:
This shows the platform independence of the ODBMS and application software, and illustrates the performance differences due to the speeds of the CPUs, the code generated by the C++ compilers, and so on.
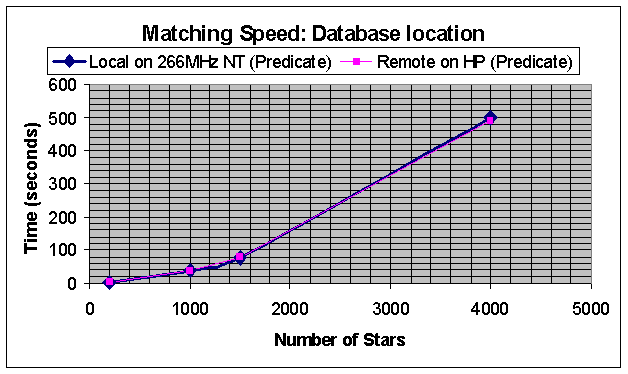
Database location independence
To demonstrate the effect on the client application speed of having the stars databases on the client's machine, or remotely served on a different machine, we measured the matching speed on the 266 MHz Pentium II PC with local databases, and with databases stored on the HP 755 workstation. The performance as a function of the number of objects in each database is shown below:
As can be seen, for these problem sizes, there is no significant performance degradation when the data are held remotely from the client application.
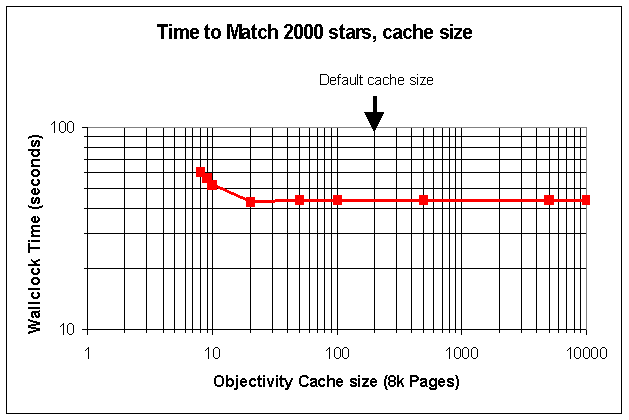
Database cache size
The Objectivity/DB cache is used to store one or more pages of the database(s) in memory, so improving performance for queries that access objects contained in cached pages. The size of the cache can be configured in the application code. For these tests, we measured the behaviour of the stars application performance with differing cache sizes when matching 2000 star objects. The default cache size is 200 pages (each page in the databases we used was 8kBytes in size). The results are shown below:
We observed some erratic behaviour of the application when using very small caches. However, the overall result shows that, for these databases, the data are all contained in the default sized cache, and no benefit is obtained by increasing it.
Tests with the HPSS NFS Interface
We have tested the operation of Objectivity/DB with a federated database located on an HPSS-managed NFS mounted file system. The HPSS machine at CACR exported a filesystem to an HP 755 workstation, where an Objectivity/DB installation was used to create a federation consisting of two 0.5 MBytes "stars" databases (see the description of the "stars" application above) located on the monted filesystem. The matching application was run successfully. Then the database bitfiles were forced off HPSS disk and into tape, and the application again run. This caused an RPC timeout in the Objectivity application during the restore of the databases from tape to disk. We then inserted a call to "ooRpcTimeout" in the application, specifying a longer wait time, and re-ran the application successfully.
In addition, we tested the performance of the NFS-mounted HPSS filesystem for simple file copies. We copied a 300 MByte file from local disk on the HP 755 workstation into the NFS filesystem, and achieved a data transfer rate of ~330 kBytes/sec. This results shows that the system is reliable for large files, the data transfer rate approximating the available LAN bandwidth between the HP 755 and the HPSS server machine.
Tests with Object Database Replication from CERN to Caltech
Together with Eva Arderiu/CERN, we have tested one aspect of the feasibility of WAN physics analysis by measuring replication performance between a database at CERN and one at Caltech. For these tests, an Objectivity/DB "Autonomous Partition" was created on a 2 GByte NTFS disk on one of the Pentium PCs at Caltech. This AP contained a replica of a database at CERN. At the same time, an AP was created at CERN with a replica of the same database. Then, an update of 2 kBytes was made every ten minutes to the database at CERN, so causing the replicas to be updated. The transaction times for the local and remote replications were measured over the course of one day. The results are shown below:
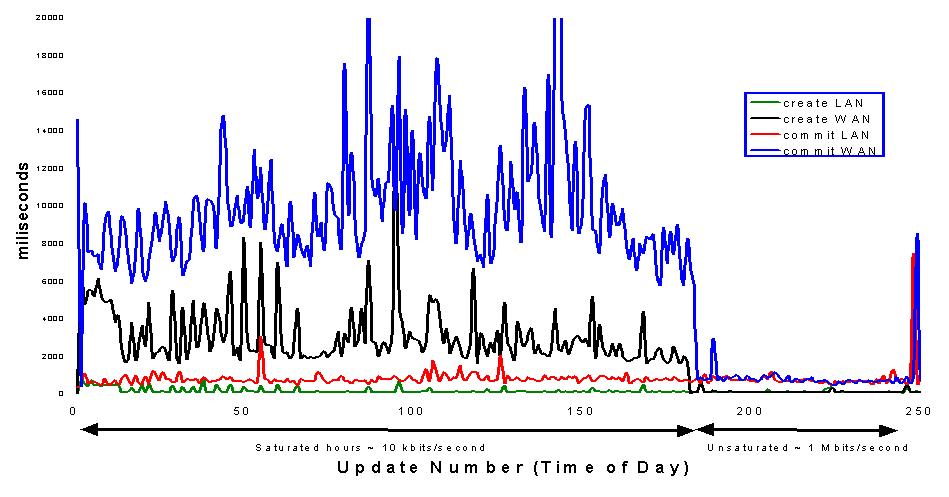 During "saturated hours", when the WAN is
busy, the time to commit the remote transaction is predictably
longer than the time to commit the local transaction. On the
other hand, when the WAN is quiet, the remote transaction takes
no longer than the local transaction. This result demonstrates
that, given enough bandwidth, databases can be transparently
replicated from CERN to remote institutions.
During "saturated hours", when the WAN is
busy, the time to commit the remote transaction is predictably
longer than the time to commit the local transaction. On the
other hand, when the WAN is quiet, the remote transaction takes
no longer than the local transaction. This result demonstrates
that, given enough bandwidth, databases can be transparently
replicated from CERN to remote institutions.
Tests with Objectivity/DB on the Caltech Exemplar
We have made tests of the behaviour of the Exemplar when running multiple Objectivity database clients. Firstly we demonstrated that a 64-CPU hypernode could be fully loaded by spreading 64 database clients evenly across the hypernode. Then we examined the performance of database client applications as a function of the number of concurrent clients of the database, and compared the results with the performance on the single-CPU HP 755 workstation. The results are shown below:
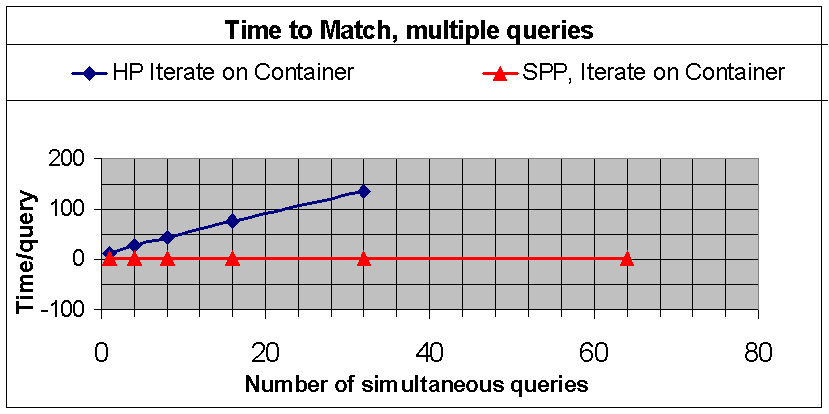
These results show that the elapsed time per query for database applications executed on the Exemplar is independent of the number of of other clients, at least in the region up to 64 clients (the tests were executed on a 64-CPU hypernode). The elapsed time per query on the single-CPU system, however, is predictably affected by the number of simultaneous queries. Of course, 64 individual workstations could also execute 64 queries in the same time, but the advantage of the Exemplar is that only one copy of the database is required, and we expect to see some benefit from clients who find the database already in the Exemplar filesystem cache.
To examine the effect of increasing the number of clients running on the 64-CPU hypernode, we ran timing tests to explore the speed with up to 256 clients, for different problem sizes. The results are shown below, for databases containing 400, 2000, and 10000 objects:
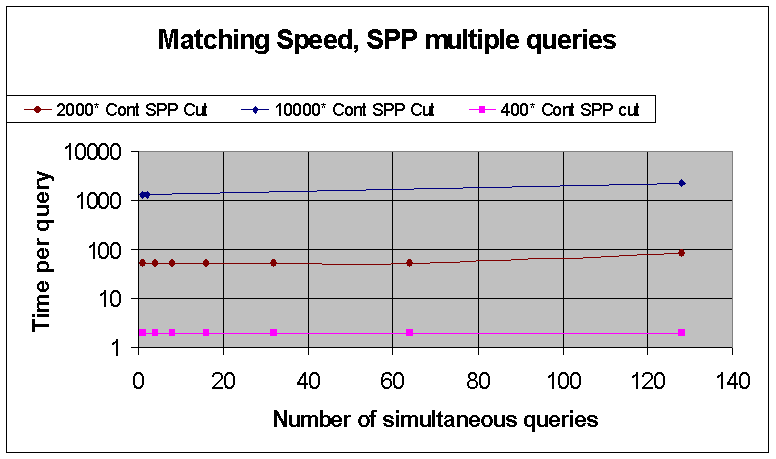
We noted some instability of the ODBMS when running with large numbers of simultaneous queries, in particular the software process that controls database locking, the "lockserver", became bogged down in some cases.
Tests with the Versant ODBMS
We have installed the Versant ODBMS on our Pentium-class PCs running Windows/NT, and ported the "stars" application to it. For both Objectivity and Versant we used Microsoft's Visual C++ version 5.0 to compile and link the applications. We measured the performance of the application as a function of the number of objects in the database, and compared these times with those obtained using Objectivity/DB.
Porting the code
Porting of the application from the Objectivity to the Versant API took about half a day. Some changes were necessary:
There were no callable functions in Versant to create or delete databases: these operations had to be carried out at the command line
There is no concept of a "federation" in Versant: instead we used two completely separate databases for each of the stars regions
The operations involved in importing the stars schema into the Versant databases was very similar to that used in Objectivity. The difference was that this had to be done separately for each Versant database, whereas in Objectivity the schema only had to be applied once to the federation.
Versant offers a "LinkVstr" feature on permanent objects: a linked list of object pointers. This proved very convenient when converting the code that ran through all objects in each database. Similar functionality can be achieved in Objectivity by the use of user-defined arrays of object IDs, but we did not investigate this.
Objectivity includes the concept of "containers" of objects, which can be used to group objects together in order to optimise access speed or simplify application code. Each container resides in a database, and iterators can be declared on the container. We found that failure to use container iterators, but instead using iterators over database objects, caused a significant performance degradation due to excessive activity in the lockserver.
The Versant "predicate" differed significantly in its API from the Versant "predicate", and we believe the Versant version to be faster.
We show below the performance of Objectivity and Versant versions of the stars application when using predicates, as well as when using pure C++ cuts:
Tests accessing ODBMS data from Java
We have installed and tested the Java bindings for both Objectivity/DB and Versant on Windows/NT, and developed Java versions of the stars application. These Java applications trivially include graphics displays of the star fields. Matching performance compared with the C++ compiled applications was typically a factor 3 to 10 slower.
The CMS H2 Test Beam OO Prototype
Data reconstruction and analysis software for a detector test beam at CERN was ported to Windows/NT. This software was developed using OO methods on Sun workstations by Vincenzo Innocente/CERN. The porting involved us acquiring the Rogue Wave Tools.h++ product. Once the OO prototype software had been ported, we copied approximately 500 MBytes of raw data from the Objectivity/DB database at CERN, across the WAN to caltech, where it was installed in a new database for testing. Vincenzo visited Caltech for one week in September 1997 to assist us in upgrading the port, developing new code, and attaching the latest data obtained from tests of a muon drift chamber prototype.
The CMS Monte Carlo Simulation, CMSIM
The CMSIM software is based on GEANT 3.21, a large Fortran application used to simulate particle interactions in material volumes. The geometry of the CMS detector, and the materials it will be constructed from, are input to the GANT program, together with model data that describe the expected particle collision products at the LHC. The program then tracks all particles through the virtual detector, and simulates their interaction with the material therein. Using this tool, physicist can estimate the sensitivity to particular events, and evaluate the acceptance of the whole detector.
We picked CMSIM version 111 to install on the Caltech Exemplar, with the aim of running some large-scale simulation of many collision events. The HP-UX binary of CMSIM ran without change on the Exemplar, demonstrating the claimed binary compatibility of the SPP-UX operating system. however, there was some instability due to floating point errors, which we traced to bugs in the software that simulated one sub-detector of CMS. These bugs having been corrected, we successfully ran several hundred simulated events, for a mean time per event of 3.5 minutes (the particular events we chose, the decay of a Higgs particle to four muons, varied somewhat in the number of secondary particles that had to be tracked per event). After rebuilding the CERN Program Library (with which CMSIM is linked) using level -O3 optimisation, we measured an average of 2 minutes per event. At this point, we submitted a run of 64 simultaneous 100-event CMSIM jobs on each of 64 CPUs in a hypernode, and obtained the following timing results:
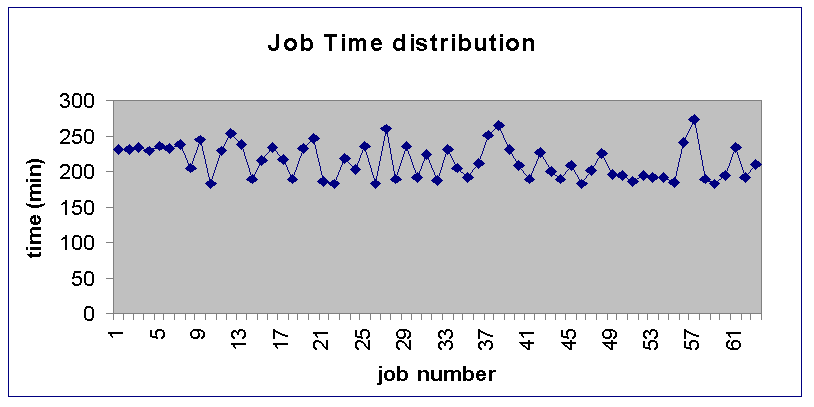
This result shows the utility of the Exemplar for running large-scale HEP Monte Carlo simulation: the times per event, and the total number of events generated during the run, represent an unbeaten record for CMSIM.
Investigate the reliability, functionality and performance of distributing objects across the WAN using schemes such as replication and copying of the object databases. Specifically:
By using and extending the Java-based DBA tool developed by RD45 at CERN
Using a 155 Mbits/sec ATM LAN connection between the Exemplar and the HP C200 workstation, compare the performance of local computation with that of remote computation as a function of the database location, its size, the available bandwidth on the LAN. By simulating different loads (terminal sessions, file transfer, Web traffic) on the LAN, explore the behaviour of the system as a function of the available connection bandwidth.
Moving a copy or replica of the CMS H2 Test Beam database between CERN and Caltech, and between Caltech and SDSC. Check the behaviour of client code that references objects in the copies or replicas that refer to non-local objects
Determine the best structure for the stored data: how to group objects to optimise access speed, how to link objects to optimise user queries, how to minimise the amount of stored data, how to minimise the amount of data being transported, how to optimise the performance of the various caching levels between the storage hierarchies. Evaluate the benefits and usability of OO software and tools when applied to real experimental physics data stored in an object database. Specifically:
With the replica on the Caltech Exemplar of the CMS H2 Test Beam database, measure the scalability of analysis tasks as a function of the number of simultaneous ODBMS clients. Simulate database workloads corresponding to tens or hundreds of client physicists running analysis tasks. Extend the tests made at CERN on a 6-CPU machine. Report on the findings at the RD45 workshop in December 1997.
Place the Test Beam database replica under file control of the HPSS system. Install the HPSS interface to the Objectivity/DB Advanced Multithreaded Server (AMS). Field-test the interface under a variety of operating conditions. With the help of HPSS experts at CACR, evaluate the performance and cache hits of the HPSS system under various database use patterns.Check the functionality of the analysis software depending on the location in the HPSS system (and client) of the target objects.
Using the CMS H2 Test Beam database, develop Java-based GUIs to the data. Determine the ease (or otherwise) of re-implementing the required sub-sets of C++ methods in Java.
Determine the complexity and performance of migrating between ODBMS, specifically:
By re-implementing, for one ODBMS, schema and applications developed in another, and by exploring possible ways of migrating "legacy" objects between ODBMS.
| Date | Description |
|---|---|
| Develop the Java-based Objectivity/DB database administration tool | |
| Install ATM link between Exemplar and C200. Investigate database object access across ATM as a function of bandwidth, object sizes, database size, database location, and so on. Emulate a possible future WAN connection by simulating various traffic patterns on the ATM link. | |
| Extend replication tests between CERN and Caltech. Include SDSC peer machine.Explore behaviour of client applications that use the replicas, when the replicas contains references to external objects. | |
| Measure scalability of analysis tasks as a function of the number of simultaneous clients. Extend tests made at CERN with a 6-CPU machine. | |
| Install Objectivity/DB on the CACR SP2, and then install the field test AMS interface to HPSS, and test it. Check the HPSS cache hit rate, and define policies for object placement in the whole system. | |
| Develop Java-based GUIs to the Test Beam database. Re-implement in Java the required C++ methods, and evaluate the usability of the Java interface. | |
| Re-implement simple (but representative of HEP applications) codes developed for Objectivity/DB using the Versant ODBMS, and measure the relative performance, functionality and scalability. Explore how legacy object data might be migrated from one ODBMS to another. |
Raw event data at the LHC will amount to several PetaBytes each year. The data is already highly compressed when it arrives out of the final trigger, and it must be stored in its entirety. Reconstruction from the raw data of physics "objects" such as tracks, clusters and jets will take place in near real time in a processing facility close to the detectors of some 10 million MIPS. The reconstructed objects will add to the data volume. Some significant fraction of the objects will then need to be replicated to outlying institutes, either across the network or, in a sub-optimal model, by air freight. Physicists located at collaborating institutes will require the same level of access to the very latest data as those physicists located at CERN. This will require continuous transport of the data across the network, or rapid decisions on where to execute analysis queries (i.e. whether to move the data across the network to a local compute resource, or whether to move the query/application to the data, and ship the results back to the physicist).
The offline software (reconstruction, analysis, calibration, event display, DBA tools, etc.) will be developed throughout the lifetime of the experiments (estimated to be at least 15 years). There will thus be many developers and many users involved in each software component, which implies a most rigorous approach to its construction.
The GIOD Project aims to: